






Bread 2 - Electric Boogaloo
I'm Christian Crowle, and I still do like bread, believe it or not.
It's been a while since I've posted to this site. Two years in fact. I did end up getting more HDD space after all, but I was living in a place with such terrible internet that I didn't dare download any bread. But now I've moved again, and can once again trawl around for some high quality bread pics.
Unfortunately, I have once again lost all my bread.
Redownloading the bread
I was assuming the CC API has changed since I last used it. I assumed correctly. Also:

So after some quick tweaks I started the script.
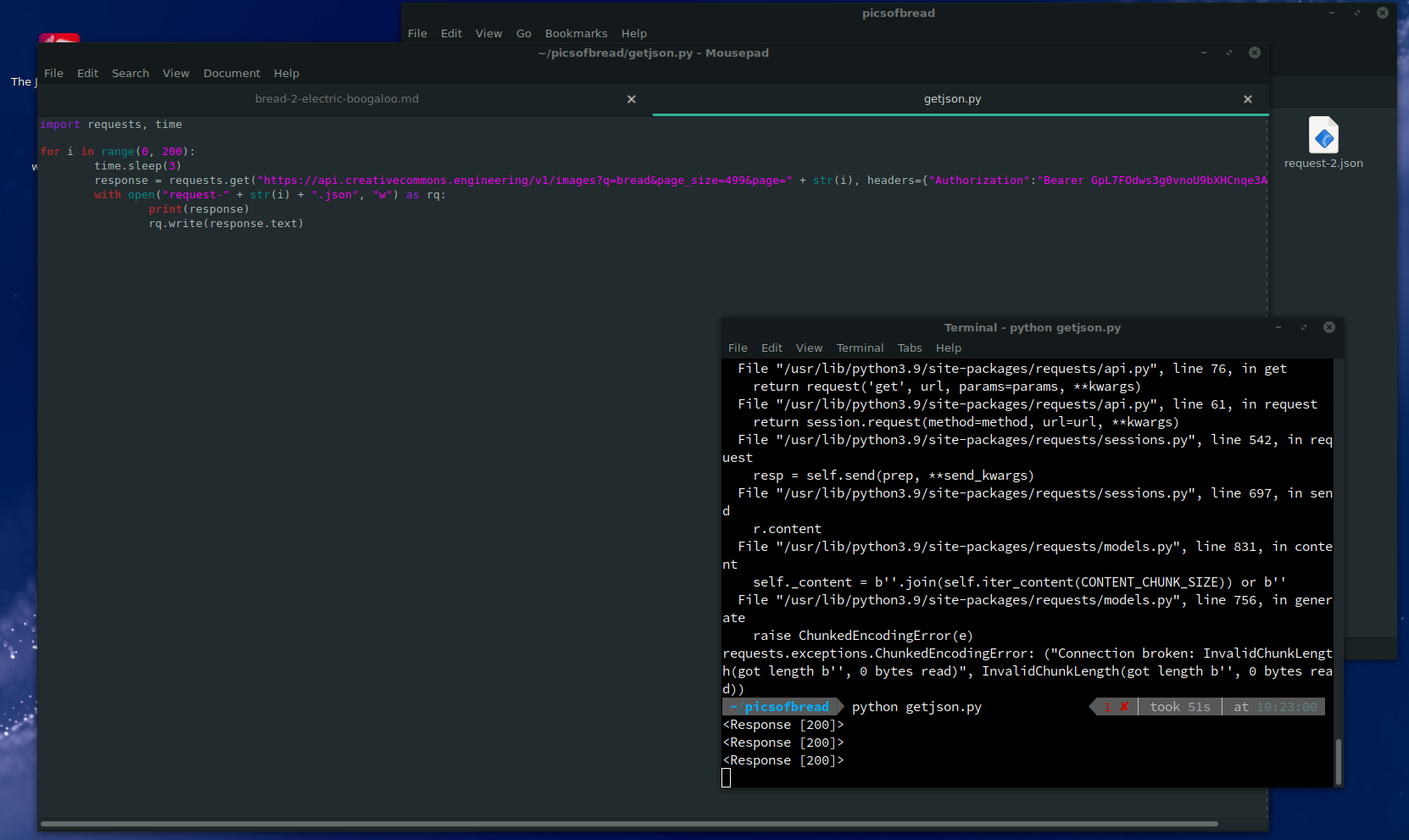
Oh wait, never mind.
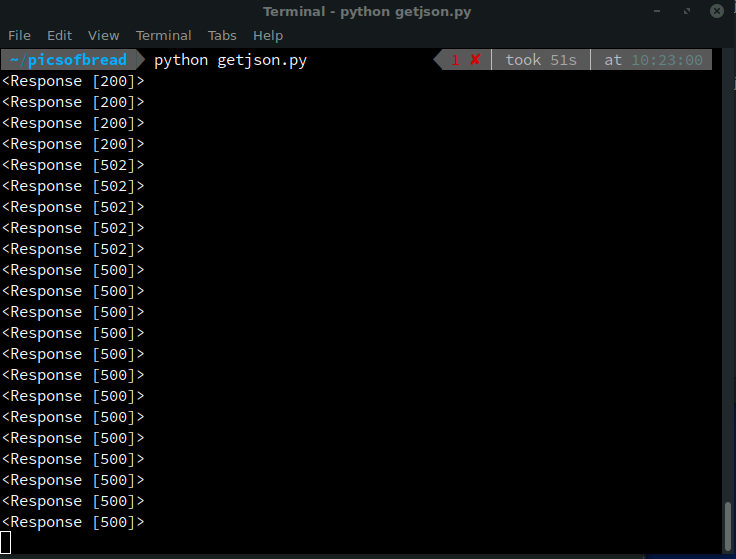
Well first of all I'm going to add the ability to restart from the latest page. That worked fine. It also lets me test certain pages if I want to.
~/picsofbread python getjson.py 5
5 - <Response [502]>
~/picsofbread python getjson.py 3
3 - <Response [200]>
That's odd... Page 3 works but 5 doesn't. Looking at CCSearch reveals that there definitely are a lot of bread pages there. Time to go low tech. I'm just gonna write a script in the Firefox dev tools to spam the "load more results" button and let it sit for a while to see what happens. Probably nothing good but you never know.

It's gonna need some cleanup because the results cease to be bread after a while (there's a creek named Bread and Cheese Creek apparently). After a couple minutes the scrolling stopped (around page 167). Let's extract our HTML. And almost crash Firefox because it's 5.2 megabytes of HTML.
According to document.images.length there are 3940 images here. With about 328 instances of the word "creek", we can assume that netted us 3612 bread pics total. Not bad, we'll process that later.
Processing them later
Each bread image is in a DIV with an aria-label that has it's description. Inside is a FIGURE, an A tag, and finally an IMG with a... thumbnail. FUCK
But it's fine, the A tag leads to the CCSearch site that contains the actual image. Let's write a shitty little script to process it.
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import requests, time, mimetypes
with open("ccsearch.html", "r") as htmlfile:
htmldoc = htmlfile.read()
soup = BeautifulSoup(htmldoc, "html5lib")
# get all of our divs
containers = soup.find_all("div", {"class": "search-grid_item-container"})
print(f"processing {len(containers)} entries...")
base_ccsearch_url = "https://search.creativecommons.org"
urls = []
for container in containers:
if "creek" not in container.get("aria-label").lower():
a = container.a
url = base_ccsearch_url + a.get("href")
urls.append(url)
print(f"got our non-creek urls. processing {len(urls)} urls... (this will take a while!)")
idx = 0
for url in urls:
idx += 1
time.sleep(2)
page_text = requests.get(url).text
real_image_soup = BeautifulSoup(page_text, "html5lib")
image = real_image_soup.find_all("img", {"class": "photo_image"})[0] # there should only be 1
image_link = image.get("src")
print(image_link)
response = requests.get(image_link)
with open(f"img/{str(idx)}{mimetypes.guess_extension(response.headers['content-type'])}", "wb") as outfile: # gross
outfile.write(response.content)
That'll work. I wait a couple seconds after each download to try to avoid 400s and stuff. That means it'll take about 2 hours to download all that bread.
Also it did end up being 3612 bread pics. Neat.
Hosting the bread
While we wait for the bread to download, we should probably work out where to put all this bread. Our main requirements:
- decent storage and bandwidth
- scalable in case we get more bread later
Other than that I really don't care. My initial thought was to do some janky stuff with rsync.net, but that probably won't work now that ftp urls don't work anywhere (thanks Google). So my first thought was a CDN. But the big ones are all "if you have to ask it's too expensive", so those are out. I eventually decided to just go through a regular web host so I don't kill the git repo this site's hosted on. Plus, there are many cheapish hosting plans that offer "unlimited" storage... Which all have a "normal small business use" stipulation. Those are out, too.
So I just googled "cheap storage vps" lol. I guess we're hosting our bread in Bulgaria. Thus all of our bread will be available at bread.picsofbread.com for your browsing pleasure.
Conclusion
Random bread should be working again on the site now. More bread will continue to be added as I process more bread datasets (breadsets, so to speak). I'll post more details about how I'm processing that bread as I go.
Oh by the way, if you have some high quality bread to send my way, please email gibbreadplz AT hotmail.com. I'd be glad to have it.